Project
Eldred Rock Scribe
I built Eldred Rock Scribe to turn hour-long investment podcasts into research-ready notes in minutes. The problem is familiar to anyone doing fundamental work: valuable ideas are buried in audio, and manually transcribing and summarizing does not scale. This project automates that workflow end-to-end while keeping inference local and costs predictable.
Architecture
The system is a React + TypeScript frontend talking to a Python Flask API over REST. A user submits a YouTube URL; the backend downloads audio with yt-dlp and FFmpeg, transcribes it with OpenAI Whisper (tiny.en), and summarizes the transcript with a locally hosted Mistral 7B Instruct model via llama.cpp (GGUF, Q4_K_M quantization). Results return as structured JSON and render in the browser — including an interactive mind map built with React Flow.
Technical highlights
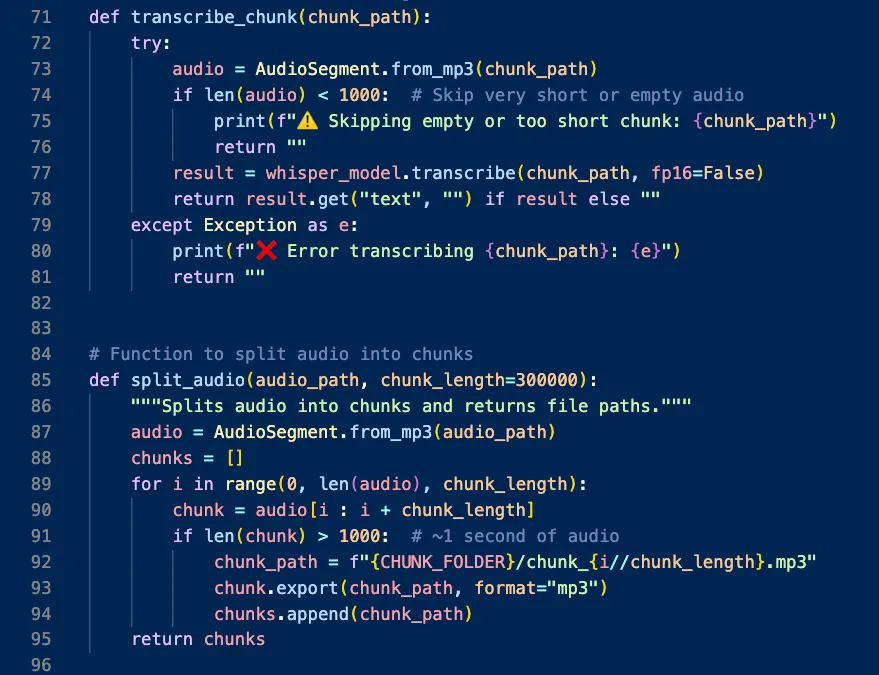
- Long-audio handling: Audio is split into ~5-minute chunks with pydub, transcribed in parallel with concurrent.futures, then stitched into a full transcript.
- Token-aware LLM summarization: Transcripts are chunked with tiktoken so each pass stays within context limits; outputs are cleaned and merged into a coherent briefing.
- Investment-oriented prompts: Summaries are tuned for buy-side workflows — business model, moat, capital allocation, risks, and key quotes — not generic abstractive summaries.
- NLP enrichment: spaCy (en_core_web_sm) supports entity extraction; LexRank (sumy) provides extractive baselines alongside generative summaries.
- Knowledge-base export: Optional one-click export writes Markdown notes to Obsidian with metadata (runtime, video length, processing efficiency).
- Companion tooling: A separate Streamlit app handles Substack articles, PDFs, and YouTube captions for non-podcast sources; email parsers extract links from RTF/.eml newsletters for batch ingestion experiments.
Why it matters
The stack is deliberately pragmatic: Whisper for robust speech-to-text, a quantized local LLM for privacy and repeatability, and a thin API boundary so the UI can evolve independently. It demonstrates full-stack delivery — from media ingestion and parallel compute to prompt engineering and interactive visualization — applied to a real research workflow, not a toy demo.
Stack: React 19, TypeScript, React Flow, Flask, Whisper, llama.cpp, yt-dlp, FFmpeg, pydub, spaCy, NLTK, BeautifulSoup, Streamlit